Random Forest Model
From the TensorFlow Decision Forests (TFDF)
This page is used to describe my CLEAN_titanic-RandomForest.ipynb notebook. Look below for a summary of my notebook and please feel free to look over my notebook
Comprehensive Analysis of the Random Forest Model
1. Beginning the Journey: Environment and Tool Setup
The journey into data analysis begins with setting up a powerful Python environment, equipped with libraries such as NumPy and Pandas. This foundational step is crucial, as it provides the necessary tools for effective data manipulation and analysis. The Kaggle Python Docker image defines this environment, offering a comprehensive suite of analytics tools ready to unravel the complexities of the dataset.
2. Data Loading: The Gateway to Analysis
Our first significant step is loading the Titanic dataset. This crucial phase involves importing the data into our Python environment, setting the stage for our analysis. Each row and column in this dataset is not just a number but a story, waiting to be deciphered and understood. This step is the beginning of our deep dive into the historical data, ready to reveal its hidden narratives.
3. Data Preprocessing: Refining the Raw Data
Data preprocessing is an essential step where we cleanse and prepare our dataset for analysis. This process involves handling missing values, encoding categorical variables, and normalizing data to ensure consistency and reliability. It’s like polishing raw diamonds, turning them into valuable insights that can be utilized effectively in our model.
4. Feature Engineering: Extracting the Essence
In feature engineering, we delve deeper into the dataset to identify and extract relevant features that significantly impact our model's predictive performance. This step involves analyzing various attributes, selecting those that provide the most value, and transforming them into a format suitable for machine learning models. It's akin to mapping the most promising paths in a vast terrain of data.
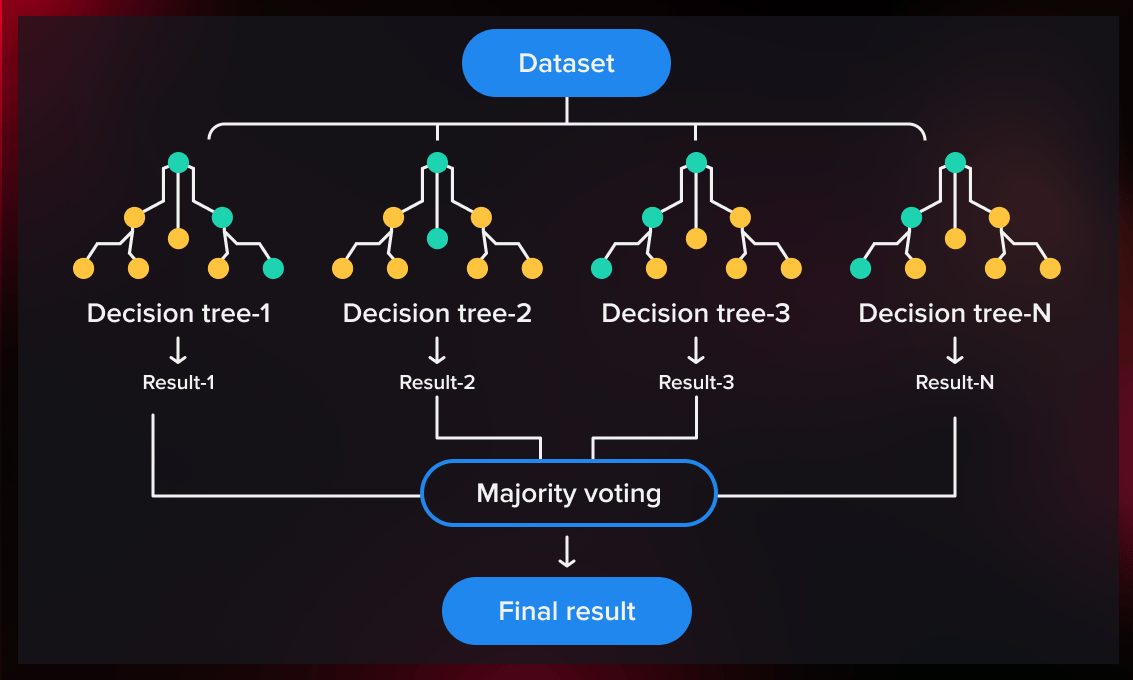
5. Model Building with Random Forest: Constructing the Prediction Framework
The construction of the Random Forest model marks a pivotal phase in our analysis. This sophisticated machine learning technique is employed to analyze the data and make predictions. The Random Forest algorithm, known for its accuracy and ability to handle complex datasets, provides a robust framework for our predictive analysis.
6. Exploring Libraries: TensorFlow Decision Forests and Scikit-learn
In our quest for the optimal model, we explore various libraries, including TensorFlow Decision Forests (TFDF) and Scikit-learn. These powerful tools offer different approaches and algorithms for building machine learning models. Their utilization exemplifies the versatility of our analysis, allowing us to compare and select the most effective methods for our dataset.
7. Hyperparameter Tuning: Fine-Tuning the Model
Hyperparameter tuning is an intricate process where we adjust the settings of our Random Forest model to enhance its performance. This critical step involves experimenting with various parameters to find the most effective combination for the model. It’s like tuning a musical instrument to produce the perfect harmony of predictions.
8. Model Training: Teaching the Model to Learn
Training the model is where we teach it to understand and learn from our dataset. This stage is crucial as the model iteratively adjusts its parameters to better fit the data. It’s akin to a learning journey, where the model gradually becomes more adept at making accurate predictions.
9. Model Evaluation: Assessing Predictive Accuracy
Model evaluation is where we assess the effectiveness and accuracy of our Random Forest model. This involves using various metrics to gauge its performance on test data. It’s a critical stage for verifying the model’s ability to predict outcomes accurately, ensuring the reliability of our analysis.
10. Gleaning Insights: Concluding the Analysis
The final step in our journey is drawing insights and conclusions from the model’s performance. This phase involves interpreting the results, understanding the model's strengths and limitations, and gleaning actionable insights. It's where we synthesize our findings, contributing to a deeper understanding of the Titanic dataset through the lens of our Random Forest analysis.